{kind=link}
让AI学着“看菜下碟”!港中大等新框架让推理长度减少90%,准确率反增17%
人类在面对简单提问时常常不假思索直接回答,只有遇到复杂难题才会认真推理。
如果 AI 模型也能像人一样决定 " 要不要思考 ",效率是否会大大提升?
近日,香港中文大学联合新加坡国立大学 Show Lab 的研究者提出了一种名为TON(Think Or Not)的新颖选择性推理框架,让视觉语言模型(VLM)可以自主判断是否需要显式推理。
实验表明,在不牺牲准确率的前提下,该方法显著减少了生成的思考链长度,使模型推理过程更高效。
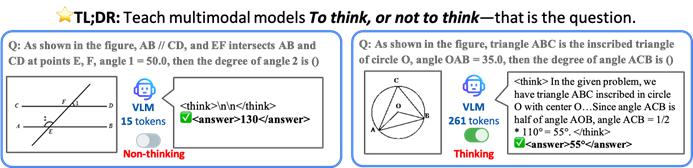
△图 1:" 要不要思考 " 的示意
左侧示例问题简单,无需完整推理即可直接得出答案;而传统方法如 GRPO 仍然生成了冗长的推理过程。右侧示例问题复杂,需要逐步推理才能得到正确答案。
TON 框架令模型能够像人类一样,对简单问题直接作答(跳过冗余思考),对困难问题则给出详尽的推理过程。
核心创新:引入 " 是否思考 " 的决策
TON 框架的灵感源自人类决策过程:并非逢问必细想,而是视问题难易选择思考或不思考。
现有强化学习方法(如GRPO,Group Relative Policy Optimization)强调让模型在回答前生成完整的推理链。这种 " 一刀切 " 的做法虽然提高了复杂任务的推理能力,但也导致对简单任务的计算浪费——模型无论易题难题都冗长 " 自言自语 " 一番。
相比之下,TON 的创新之处在于让模型首先判断 " 要不要思考 "。这一选择性推理策略意味着模型将推理与否视作一项独立技能来学习,而非默认总是执行推理。
正如作者所言,他们关注的是 "When to think" 而非传统方法研究的 "How to think"。

△图 2: GRPO 与 TON 的采样过程对比示意图
其中,q_1 表示问题,{o_1, … , o_5} 为生成的响应集合,每个响应包含思维过程 T(圆形)和答案 S(三角形)。TON 方法能够从空思维 T_{nn} 中进行采样,从而 GRPO 显著提升了响应多样性。
为实现这一目标,研究者设计了两阶段训练机制使模型掌握选择性推理的本领。
第一阶段是有监督微调(SFT)引入的 "思想丢弃(Thought Dropout)"。具体来说,他们将模型训练数据中原本的
换言之,模型有约一半概率看到示例是不包含中间思考步骤的。这一步相当于教会模型输出一种 " 不思考 " 的格式,让模型知道直接回答也是允许的。
值得一提的是,研究者还用了一个 " 反向思考 " 策略来自行构造高质量的思考过程数据,以辅助模型学习何时可以跳过推理。
第二阶段是强化学习的GRPO 优化训练。在这一阶段,模型被鼓励自主探索何时应该思考、何时跳过,以最大化任务奖励。
具体做法是:模型针对同一输入图像和问题生成多个候选响应,其中有的包含完整思考链,有的为空想(即无思考过程直接回答)。
接着通过比较这些候选的结果正确性和格式,给予奖励并用 GRPO 算法更新策略,引导模型学会在确保正确率的前提下尽量跳过不必要的推理。
经过这两阶段训练,VLM 模型便掌握了 " 一题一策 " 的选择性思考能力:简单题跳过推理,复杂题老老实实推理。
实验结果:思考效率大幅提升,准确率不降反升
作者在多个具有不同推理难度的视觉 - 语言任务上验证了 TON 的效果,包括CLEVR(简单图形推理)、GeoQA(数学几何问答)以及AITZ(Mobile 智能体导航任务)等。
在这些基准上,TON 框架展现出惊人的效率提升——平均推理输出长度最多减少了 90%!
例如,在 CLEVR 数据集上,TON 将模型每次回答所需的生成文本长度减少了近九成,而在 GeoQA 上也减少了约 65%。
值得注意的是,模型准确率不仅没有下降,反而在某些任务上有所提高。
以问答 GeoQA 为例,TON 模型相比始终思考的 GRPO 基线,准确率提升了最高 17 个百分点。
这意味着,让模型学会 " 偷懒 " 跳过无用思考不仅节省计算,还可能带来性能的 " 免费午餐 "。
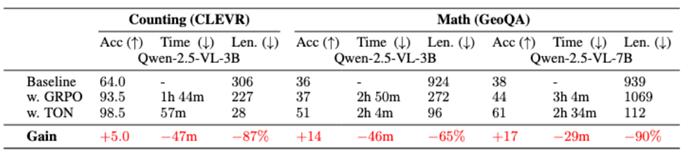
△图 3:TON 和 vanilla GRPO 在 CLEVR 和 GeoQA 上的结果对比
TON 平均推理长度最多减少了 90%,并且准确率不降反升。
另外,研究人员对比了 TON 在 AITZ 的分布外数据集上面的效果,效果可以和 vannila grpo 保持一致,但是输出长度从 3k 减少到了 900,更加高效。
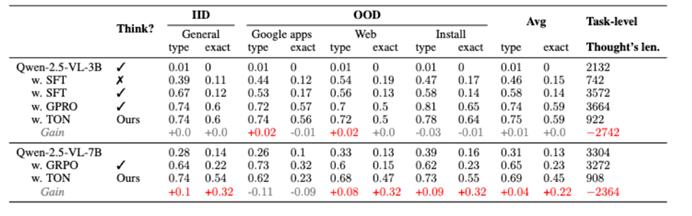
△图 4: TON 在 AITZ 的不同 domain 测试集上面的表现。
由图 4 可以看出效果保持一致,但是 task level 的长度从 3k 减少到了 900。
研究人员进一步测试了训练过程的更多指标,发现训练过程中,TON 输出空内容

△图 5: TON 和 vanilla GRPO 在训练过程中的 reward 可视化图
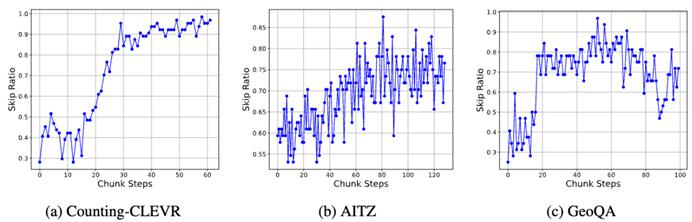
△图 6: TON 和 vanilla GRPO 在训练过程中的输出空思考的比例可视化图
另外发现,简单的任务更容易跳过思考(比如 CLEVR),但是难的任务反而不容易跳过(比如 GeoQA),展现出模型在强化学习的过程中,自适应的针对问题的难易程度,学习何时该思考合适不思考。
在不降低准确率的情况下减少将近九成的推理步骤,这对大型模型的实际部署带来了切实的益处。
一方面,推理效率的提升意味着更快的响应速度和更低的算力消耗。这对于需要实时互动的多模态助手、机器人等应用尤为重要。
另一方面,TON 展现的" 按需思考 "模式让 AI 更接近人类的思维习惯——该思考时就认真思考,该果断时则不拖泥带水。这种人性化的推理策略有望提升模型在推理任务上的通用性和可靠性。
总的来说,TON 提出了一个值得关注的方向:并非一味追求更长的思维链,而是先问问自己 " 要不要思考?"。
未来,这类机制可能成为提升大模型实用性的一个重要途径。
以下是两个代表性的 TON 系列模型,它们在不同任务上展示了这一机制的实际应用效果。
例子 1
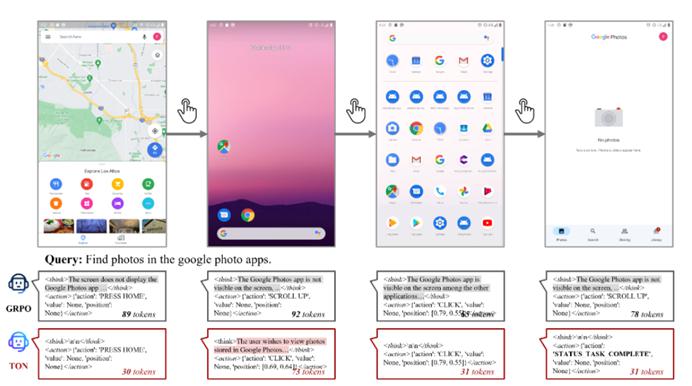
△图 7: GRPO 与 TON 在 GUI agent AITZ 上的对比
TON 在多步移动导航过程中自适应跳过不必要的思考步骤,在保持任务准确性的同时实现了比 GRPO 更高的解码效率(本例中节省了 60% 的 token 消耗)。
例子 2

△图 8: CLEVR 中思考模式与非思考模式的对比图示
TON 展示了选择性激活推理的能力——仅在需要时启动思考机制,而 GRPO 则不加区分地为所有情况生成推理轨迹。
论文地址:https://arxiv.org/abs/2505.16854
代码地址:https://github.com/kokolerk/TON
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见