{kind=link}
谷歌年度大招:所有AI模型全升级一遍!Gemini2.5大杯中杯霸榜前二,新版视频/图像模型亮相
原生多模态输入输出、智能体、联网搜索……所有前沿 AI 能力集成在一起会怎么样?
谷歌最新版 Project Astra 展示了终极 AI 助手的能力:
实时观察周围环境,搜索资料指导小哥修自行车,零件不够还能自动电话询问周边商店有没有货。
在最新的 I/O 大会上,谷歌连续放大招,就好像大招不要钱。
现有 AI 模型全部更新一遍
原有的产品用 AI 重做一遍
实验性新产品也推出了一箩筐
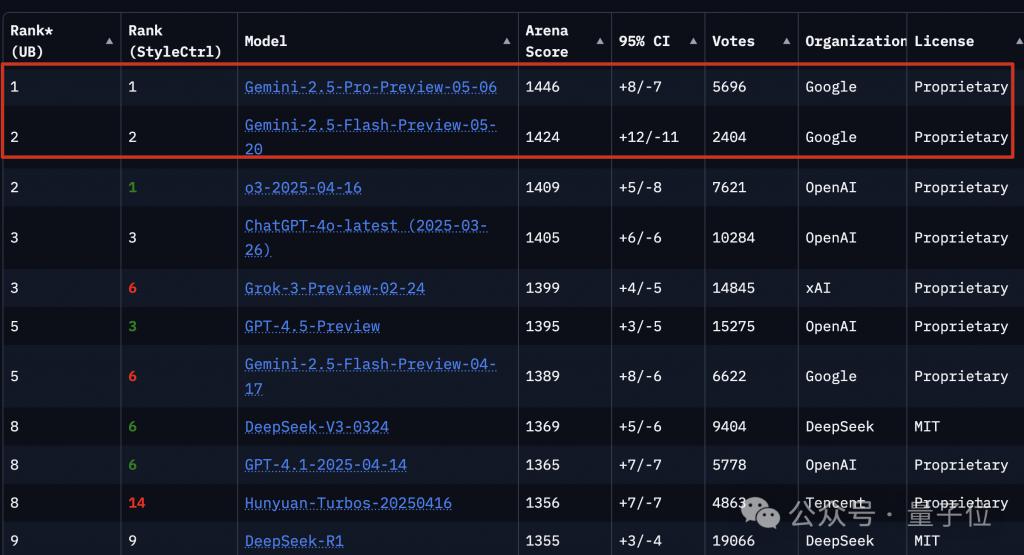
Gemini 2.5 Pro 和 Gemini 2.5 Flash 的预览版已霸榜竞技场前两名。
视频生成模型 Veo 3,实现视频与音频的原生集成,除音乐和音效,甚至是角色间的对话语音都能生成,画面上还能同步口型。
图像生成模型 Imagen 4,图像更加丰富,色彩更加细腻,细节更加逼真。

……
传统产品方面,谷歌搜索增加端到端 AI 搜索模式,整合推理和多模态分析能力,将问题分解为子问题,并同时发出多个查询,更深入地探索网络。
视频会议 Google Meet,支持实时的双语翻译配音,并保留对话双方的音色,首批英语 - 西班牙语支持已上线,后续将添加更多语言。
Chrome 浏览器,直接集成 Gemini 模型,可快速总结内容,或根据当前网页上下文完成任务,无需切换标签页。
新产品方面,原裸眼 3D 视频通话 Project Starline,升级为 AI 驱动的 3D 视频通信平台 Google Beam。
使用一系列摄像头从不同角度捕捉画面。然后借助 AI 将视频流合并,在 3D 光场显示屏上呈现画面——头部追踪精度可达毫米,帧率高达每秒 60 帧。
AI 视频模型与光场显示技术的结合创造了维度感和深度感,使用户能够进行眼神交流,观察微妙的表情,建立理解和信任,就像面对面一样。

此外还有异步 AI 代码助手 Jules,它在后台运行时人类用户可以专注于其他任务。
AI 电影制作工具 Flow,集成多款多模态模型,让创意变成故事。

与墨镜品牌 Gentle Monster 和 Warby Parker 合作打造的 AI 眼镜,配备摄像头、麦克风和扬声器,可与手机协同工作,无需把手机从兜里掏出来就能访问 APP。
Gemini 模型加持下,AI 眼镜能够看到和听到你的一举一动,从而了解你的处境,记住重要事项,并全天提供帮助。
各部分详情下面一一来看。
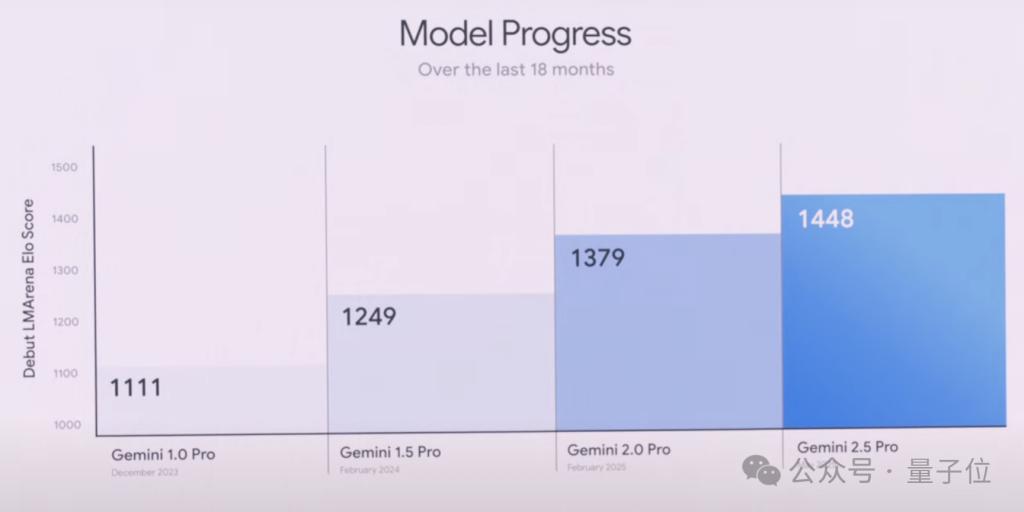
Gemini 2.5 系列模型全新升级
Gemini 2.5 系列,2.5 Pro、Flash 均进行了一波升级。
首先来看 Gemini 2.5 Pro,除了在学术基准测试中表现出色外,现在还以 1415 的 ELO 分数领先于热门编码排行榜 WebDev Arena,比上一个版本提升 142 分:
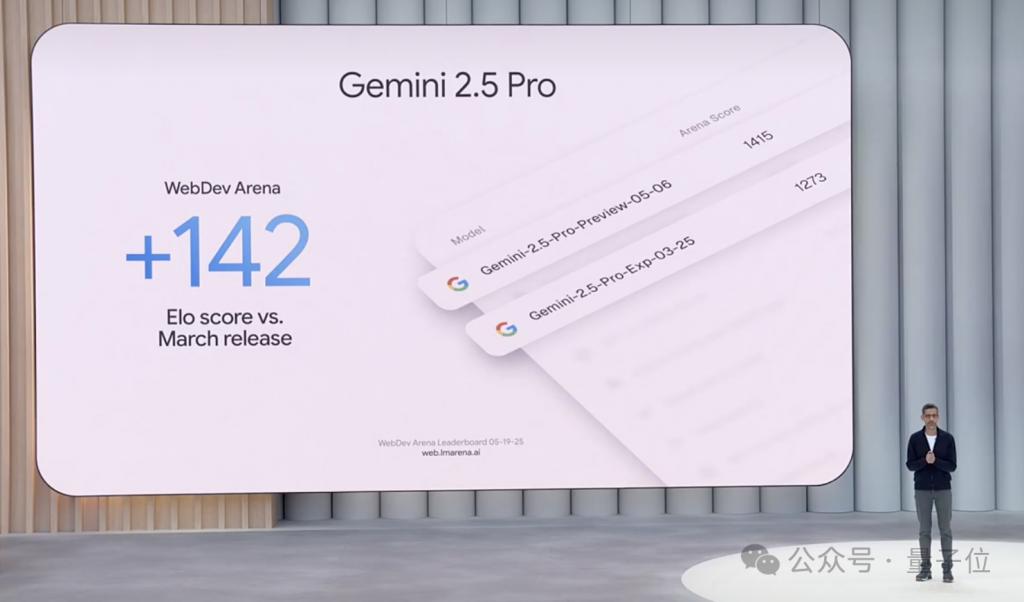
同时霸榜于评估人类偏好各个维度的 LMArena:
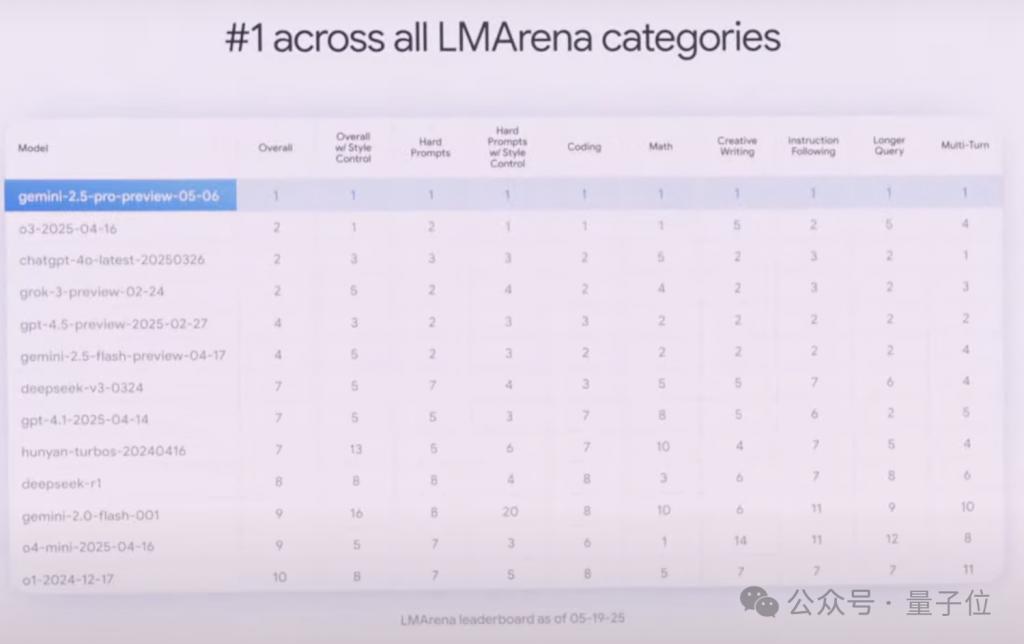
据介绍,凭借其百万 token 上下文窗口,2.5 Pro 具有更强的长上下文和视频理解性能。
2.5 Pro 还整合了谷歌与教育专家合作开发的 LearnLM 模型系列,在评估其教学法和有效性的直接对比中,教育工作者和专家在各种场景中更青睐 2.5 Pro。
更值得一提的是,2.5 Pro 全新引入了Deep Think增强推理模式。据介绍,该模式使用新的技术,允许模型在回应前同时考虑多种假设。
效果如何?
2.5 Pro 在 2025 年 USAMO 这种超难数学基准测试上得分惊艳,在编程比赛级别的 LiveCodeBench 上也有优势,在测试多模态推理的 MMMU 基准中获得 84.0% 的分数。

不过,谷歌表示 Deep Think 需要更多时间进行前沿安全评估,目前仅将通过 Gemini API 向可信测试人员开放该功能。
2.5 Flash 也进行了升级,在推理、多模态、代码和长上下文等关键基准测试中均有改进,同时效率更高,在谷歌的评估中使用 token 减少了 20-30%。
全新 2.5 Flash 现在已在 Google AI Studio、Vertex AI 和 Gemini app 中提供 preview。

不仅如此,Gemini 2.5 系列还引入了不少新功能。
1、原生音频输出功能 &Live API 改进
Live API 推出了视听输入和原生音频对话的 preview 版本,用户可以直接构建更自然、更具表现力的 Gemini 对话体验。
模型可根据用户要求调整语调、口音和说话风格,感情变化听得见。
谷歌还为 2.5 Pro 和 2.5 Flash 推出了文本转语音(TTS)的新功能。首次支持多扬声器,通过原生音频输出实现双语音合成,即模拟两个不同的声音角色同时或交替发声,支持 24 种不同语言。
该文本转语音功能现已在 Gemini API 中可用。
2、电脑操作能力
谷歌正将 Project Mariner 的电脑操作能力引入 Gemini API 和 Vertex AI。
支持多任务处理,最多可同时执行 10 个任务,并且新增 "Learn and Repeat" 功能,让 AI 学会自动完成重复性任务。
3、为提升开发者体验,Gemini 2.5 增加三大实用功能:
thought summaries,会将模型的原始思考过程整理成带标题、关键细节和模型操作信息(如工具调用)的清晰格式,帮助开发者更透明地了解模型思考过程。
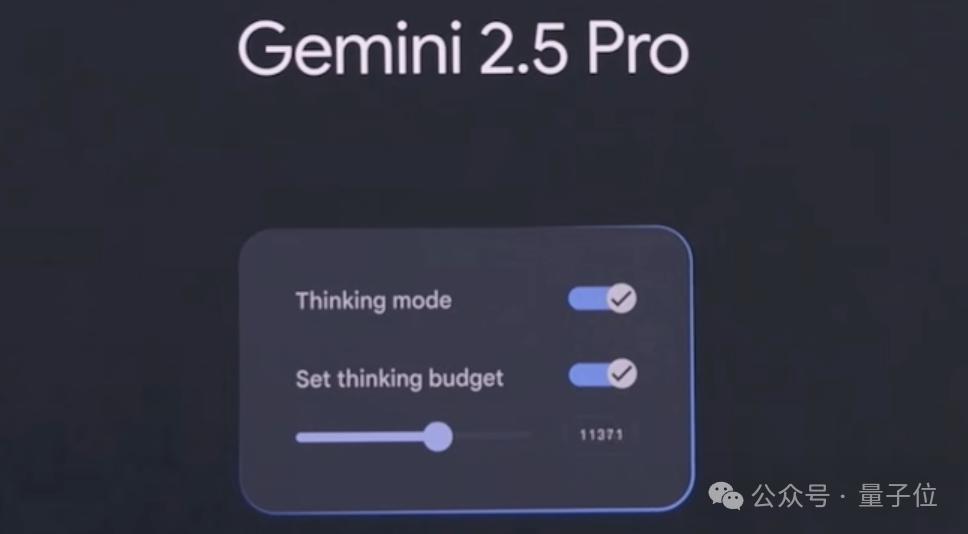
thinking budgets,让开发者可以控制模型使用多少 token 进行思考;
Gemini SDK 兼容 MCP 工具,实现与开源工具的更轻松集成。
关于谷歌 Gemini 的下一步,谷歌 DeepMind CEO 哈萨比斯表示,他们正努力将其最优秀 Gemini 模型扩展为一个 " 世界模型 ",使其能像人类大脑一样通过理解和模拟世界来制定计划、想象新体验。
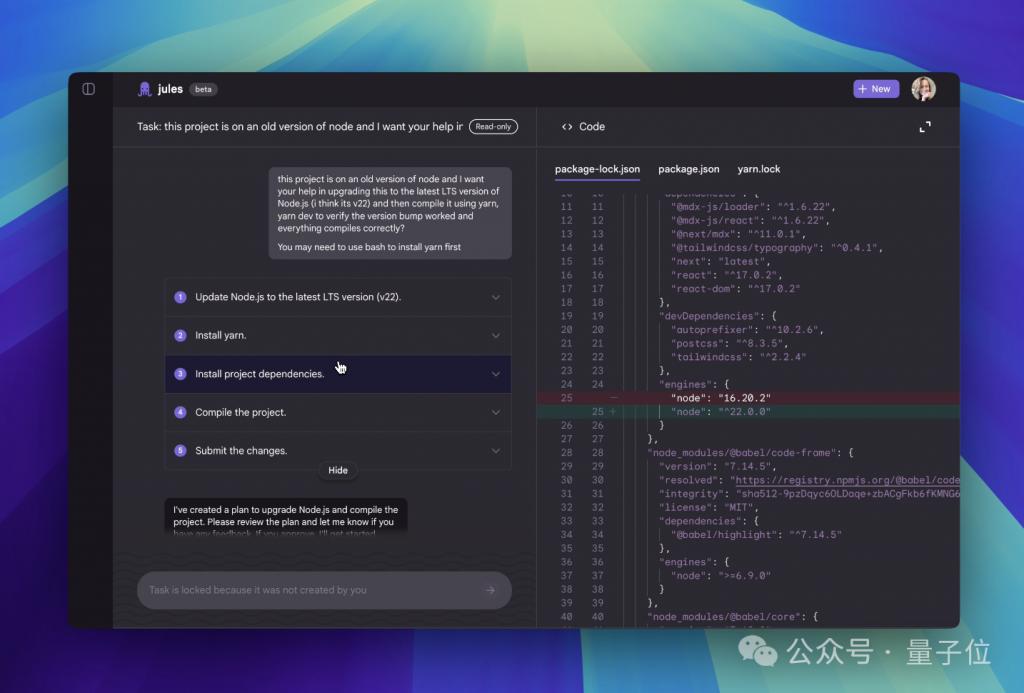
异步代码助手 Jules
异步代码助手 Jules 正式进入公测阶段,全球开发者无需等待就能体验。
Jules 会把你的代码库克隆到安全的谷歌云虚拟机中,全面理解项目上下文,可以写测试、构建新功能、提供音频更新日志、修复 bug,以及更新依赖版本。
它以异步方式工作,让你可以专注于其他任务,完成后会展示其计划、推理过程和更改内容。私有库中的工作默认保持私密,Jules 不会用你的私有代码进行训练。
得益于 Gemini 2.5 Pro 的支持,Jules 拥有目前最先进的编码推理能力。结合云 VM 系统,它能处理复杂的多文件变更和并发任务。
公测期间完全免费,但有使用限制,平台成熟后预计将引入付费方案。
谷歌搜索引入 AI Mode
搜索方面,这次 I/O 大会宣布将 AI Mode 正式引入搜索引擎,面向美国用户全面开放。
AI Mode 是以 Gemini 2.5 为核心重构的搜索引擎,集成了 Gemini 最前沿的能力,提供端到端的 AI 搜索。
它采用query fan-out技术,自动将问题分解为多个子话题并同时搜索,从而比传统搜索更深入、更全面地挖掘网络信息。
谷歌预告了 AI Mode 未来的一系列功能,比如:
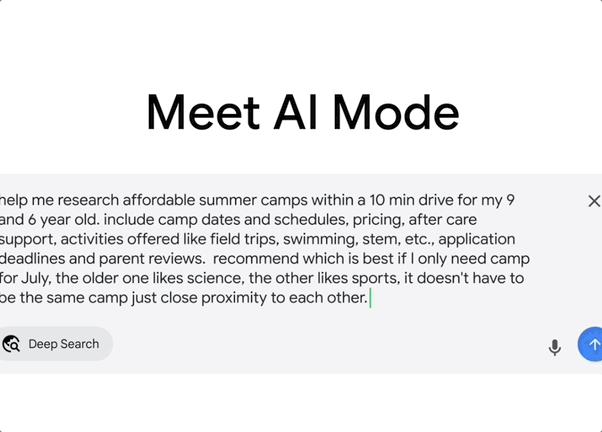
Deep Search 深度搜索模式,能自动发起上百次搜索,跨领域整合信息并生成引用详尽的专家级报告,节省大量人工研究时间。
Search Live 实时互动搜索,用户只需在 AI Mode 下轻触 "Live" 图标,对着手机摄像头提问,AI 就能看懂画面内容并给出实时的语音解答和相关资源链接。
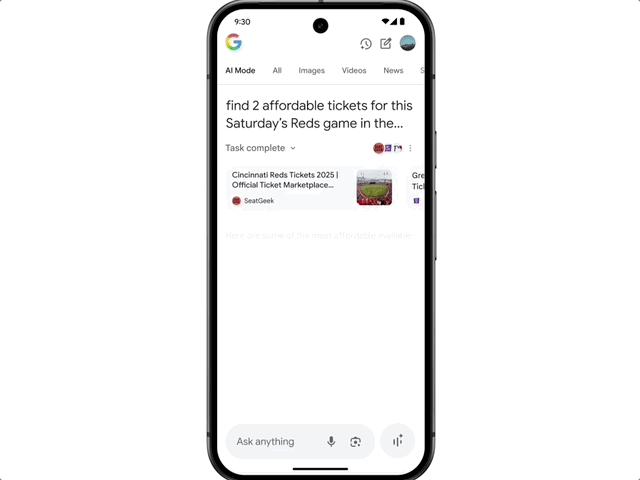
还有 Agent 能力,用户想买音乐会门票,只需说一句话,AI Mode 就会跨平台搜罗各大网站的票务信息,锁定最优选项,填好订单信息。用户只需确认符合需求的选项,即可在偏好的网站完成购买。
谷歌还重点展示了 AI Mode 所带来的全新购物体验。
新购物体验将 Gemini 的智能与 Shopping Graph 结合,集成了 500 亿 + 优质商品信息,可帮助用户浏览、梳理需求并筛选商品。
当用户决定购买时,全新的智能结账功能会按照符合预算的价格轻松完成交易。
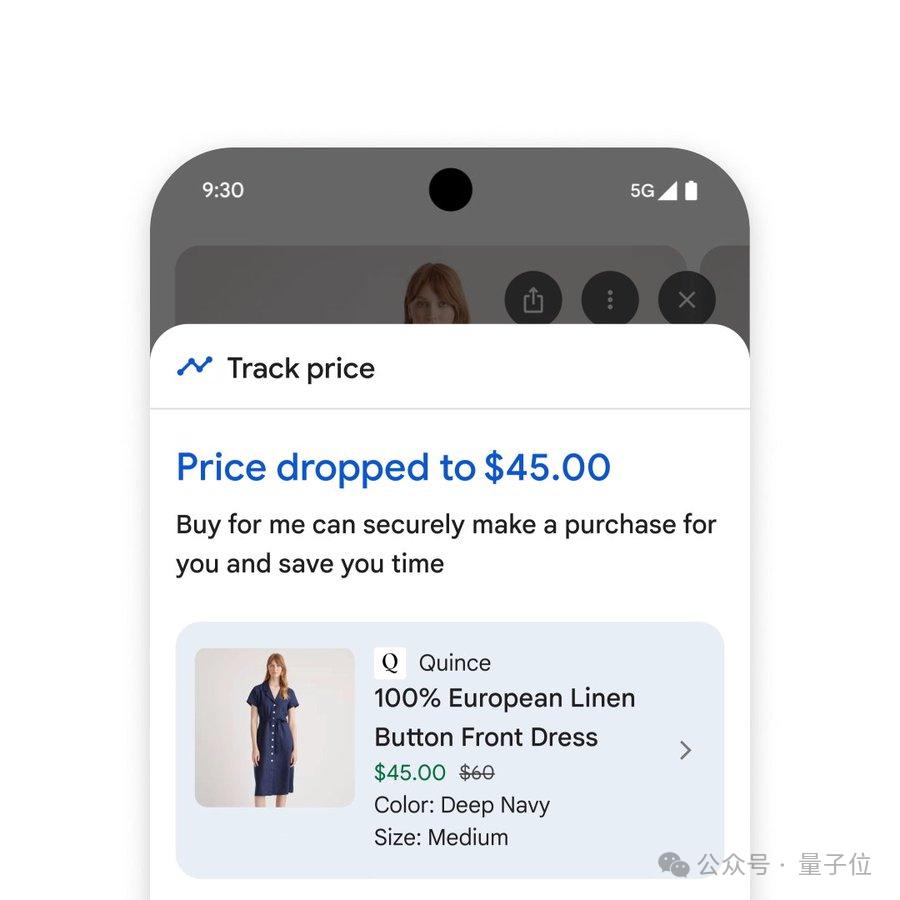
只需在任意商品页面点击 " 跟踪价格 ",设置尺寸、颜色和预算金额等,当价格下跌时,用户会收到通知,确认购买细节后点击 " 代我购买 ",系统就会自动将商品加入购物车,并通过 Google Pay 安全完成结账。
另外在购买衣服时,它还提供虚拟试穿工具,支持使用用户自拍照。只需上传一张自拍照,就能在海量服饰中随意试穿,AI 模型能精准还原不同材质的垂坠和褶皱。

多模态模型全线升级
在多模态方面,谷歌还重磅推出了最新视频生成模型 Veo 3、图像生成模型 Imagen 4。
Veo 3 首次实现原生音画同步生成,无论是城市街道的车流声、公园中的鸟鸣,甚至是角色对话,均可通过文本提示生成。
用户只需用提示讲述一个短故事,模型就能生成栩栩如生的视频片段。
从文本 / 图像提示到现实世界物理效果的模拟和精准的口型同步,Veo 3 在各维度均表现出众。
Veo 3 已向美国 Ultra 订阅用户开放,企业用户也可在 Vertex AI 平台调用。
在推出新模型的同时,Veo 2 也增添了多项新功能,包括参考驱动视频生成、相机控制、画面扩展以及对象添加和移除功能。这些功能已在 Flow 中提供,未来几周内将在 Vertex AI API 中推出,并在未来几个月内集成到更多产品中。
谷歌最新图像生成模型 Imagen 4 则兼具速度与精度,速度比上一代快 10 倍,生成的图像在精细细节上表现惊人,从复杂织物、水滴到动物皮毛均清晰逼真,同时擅长写实与抽象风格。

Imagen 4 支持多种纵横比与最高 2K 分辨率,文字拼写与排版能力显著提升,轻松创作贺卡、海报、漫画。

目前 Imagen 4 已在 Gemini app、Whisk、Vertex AI 等上线。
除此之外,谷歌还介绍了新一代 AI 电影制作工具 Flow,它专为创意人士设计,集成了谷歌最强的视觉模型(Veo、Imagen 和 Gemini)。
Flow 具备卓越的提示遵循能力,可输出震撼的电影级画面。背后 Gemini 模型让提示输入直观易用,用户可通过日常语言描述创意愿景,支持导入自有素材创建角色,或利用 Imagen 的文生图功能在 Flow 中生成故事要素。
一旦创建了角色或场景,即可以在不同片段与场景中连贯复用这些要素,也可以用单一场景图像启动新镜头。
即日起,美国 Google AI Pro 与 Ultra 订阅用户可率先使用 Flow。
One More Thing
在大会现场,CEO Sundar Pichai 还透露了这样一个数据。
去年 4 月,谷歌产品和模型 API 合计每月处理 9.7T 的 tokens。
一年时间过去,这个数据增长到 50 倍,每月处理 480T+ tokens。
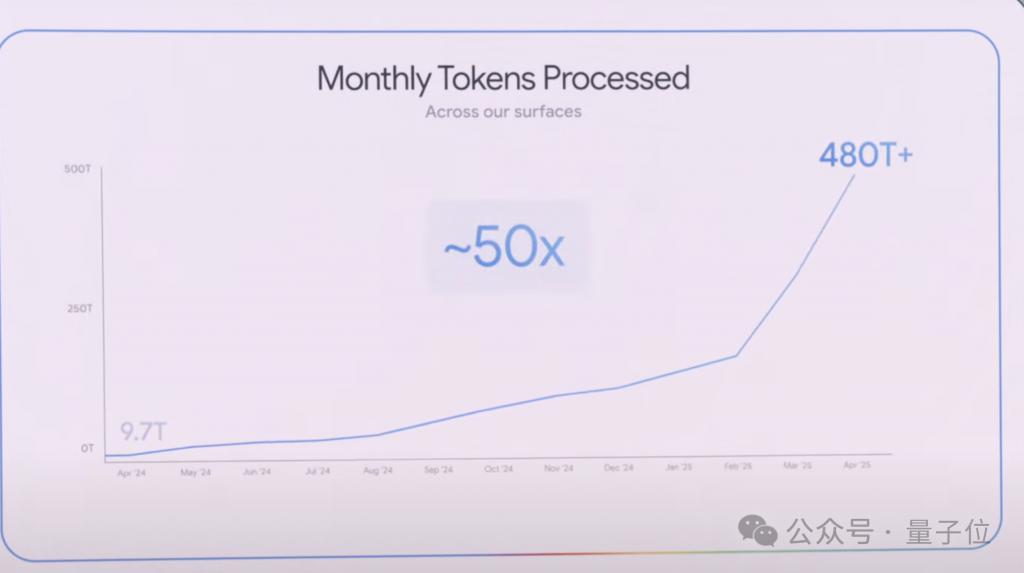
世界采用人工智能的速度比以往任何时候都快。
视频回放:https://www.youtube.com/watch?v=o8NiE3XMPrM
参考链接:
[ 1 ] https://google-i-o-2025-press-site.prezly.com/
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!