{kind=link}
首次解释LLM如何推理反思!西北大学谷歌新框架:引入贝叶斯自适应强化学习,数学推理全面提升
推理模型常常表现出类似自我反思的行为,但问题是——
这些行为是否真的能有效探索新策略呢?
对此,西北大学与 Google、谷歌 DeepMind 团队质疑了传统强化学习与反思的关系,并提出了贝叶斯自适应的强化学习方法,首次解释了为什么、如何、以及何时应该反思并探索新策略。

通过对比分别使用传统强化学习和新方法训练的模型,研究人员发现:
在完成 " 模型需要在 3 步内输出三个连续相同字符 " 这一合成任务中,传统 RL 往往一条路走到黑,而新方法懂得排除无效假设,适时切换新策略。
并且在数学推理任务中,新方法在大部分基准和模型上都取得了更高的准确率,同时为解出题目所耗费的 token 数量更少。
更有意思的是,团队发现反思次数并非决定性能的唯一因素,一些基础模型往往出现很多徒劳的反思,并没有带来实质的信息增益。
下面详细展开。
贝叶斯自适应强化学习激发反思性探索
直观来说,测试时试错的步骤只有当能带来信息增益的情况下才有益,然而人们并没有在 RL 训练中告诉模型试错和反思带来的信息增益。
事实上,现有的基于马尔可夫假设的强化学习范式存在天然的局限——探索(exploration)仅发生在训练阶段,代理在部署(测试)时通常只会利用(exploit)训练中学到的确定性策略。
并且马尔可夫假设使得 RL 代理只根据当前状态做决策,历史信息(比如试错并回朔的思考过程)对策略的影响都被只压缩到当前状态表示中。
研究者指出,这种传统范式可能导致模型通过记忆训练解答就已经拿到高分,而不需要真正学会反思;模型内部思考的试错也并不能提供信息增益。
那测试时的反思性探索真的有用吗?如何才能学到有效的反思性探索策略呢?

为了回答上述问题,研究者研究了与传统 RL 不同的贝叶斯自适应 RL 框架,简称 BARL。
它的核心思想是将 LLM 的反思性探索转化为贝叶斯自适应强化学习问题来处理,通过引入对环境不确定性的建模,让模型在推理过程中自适应地进行探索。
简单来说,BARL 不再局限于传统 RL 的马尔可夫假设,而是考虑了 MDP 的不确定性(比如不同策略对一道题的有效性),于是需要把所有历史的观察(包括奖励反馈)纳入决策中。
这种框架天然地平衡了奖励最大化的利用和信息获取的探索。
具体而言,在 BARL 中,团队假设模型面对的是一个存在未知要素的任务,可以用一组假设的 MDP(马尔可夫决策过程)来描述这些不确定性。
模型对每个假设 MDP 保持一个后验概率(belief),随着推理过程不断更新。
每当模型选择一个动作(如生成下一个思维步骤),都会根据观察到的结果更新对各个假设的信念。
BARL 的目标策略并非针对单一确定环境优化,而是直接优化在后验分布下的期望累积回报。这意味着模型在决策时,会考虑 " 我这样做的收益是多少,同时这样的行动能多大程度减少不确定性?"。
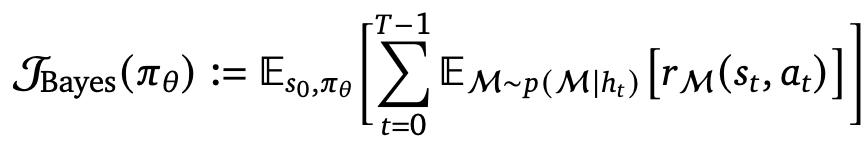
BARL 明确地将测试时的表现纳入优化目标,通过最大化后验下的期望回报鼓励模型考虑未知情况。
模型明白只有主动探索才能在未知情境下保持高收益,因此反思是为了获取关键信息,避免一条路走错到底。
简而言之,BARL 让模型意识到——
适时反思、多一种尝试可能带来更高的回报,这正是反思行为得以涌现的动机。
全新推理模型强化学习算法
研究者针对推理模型给出了BARL 决策的数学形式,其中核心是如何计算后验的期望值:

该公式针对多个候选答案(比如 best-of-N 里的 N 个答案)计算了预期回报加权求和,权重一方面是模型认为该候选答案的好坏,另一方面还包含了一个 " 校正项 " ——用来衡量实际观察结果与模型预期的偏差。
正是这个校正项充当了反思信号:如果某个策略原本被模型高度看好,但奖励反馈结果不尽如人意,那这个差异会迅速降低该假设的权重,提醒模型 " 也许该换一种思路了 ",这正回答了模型应该何时进行反思和探索。
通过这种机制,BARL 的决策公式指导模型在每个步骤判断是否需要反思、何时切换策略。
这也是 BARL 反思性决策的精髓——让模型基于贝叶斯后验来权衡 " 继续当前思路 " 还是 " 尝试新思路 "。
这种更新过程鼓励模型拼接和切换不同的推理策略,就像把多条可能的解题思路串联起来,并在中途发现某条思路行不通时迅速切换到另一条。
BARL 通过端到端的 RL 优化自动实现了这一点,可谓以原则化的方式赋予了 LLM 在推理过程中的 " 何时反思、如何反思 " 的指南,达到了以一条长 CoT 线性化 best-of-N 的效果。
合成任务案例:更清楚的对比 RL 和 BARL
为了直观展示 BARL 如何在测试时展现反思探索能力,作者设计了一个合成任务:模型需要在 3 步内输出三个连续相同的字符(0/1/2),才能获得奖励。
训练阶段,提示(prompt)字符只会是 0 或 1,模型学会了对应输出 000 或 111 来拿到奖励;但是测试时,提示字符变为了 2。
直觉上,训练时学到的确定性策略在遇到新字符时将不再有效,需要模型即时探索正确的输出模式。
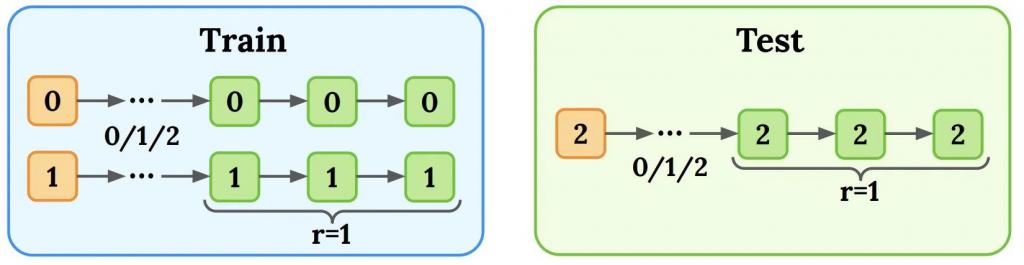
让两个模型来挑战这个任务:一个用传统马尔可夫 RL 训练,另一个用 BARL 方法训练。
Markovian RL 很快就最大化了训练准确率,几乎将这些答案背了下来。
BARL 在训练中同样学会了正确输出模式,但更有趣的是,它同时学会了根据不确定性来调整策略——这一点要等到测试才能看出差别。
测试阶段揭示了截然不同的行为。即当提示变为新字符 2 时,Markovian RL 由于在训练中只记住了固定的输出(000/111)无法泛化,因此几乎总是答错,测试准确率接近于零。
而 BARL 代理则展现出 " 反思 " 能力。它会先尝试某个策略,如果初步尝试未获得奖励,就迅速反思切换,尝试另一种可能的序列。
下图形象说明了 Markov RL 和 BARL 在该合成任务中的决策差异——
Markov 策略一条路走到黑,BARL 策略则懂得排除无效假设,适时切换新策略。
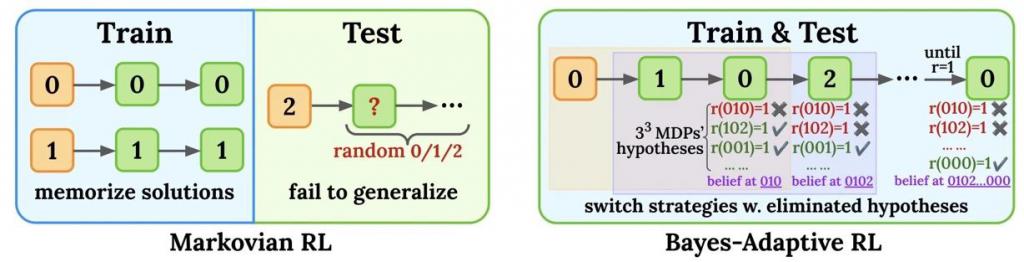
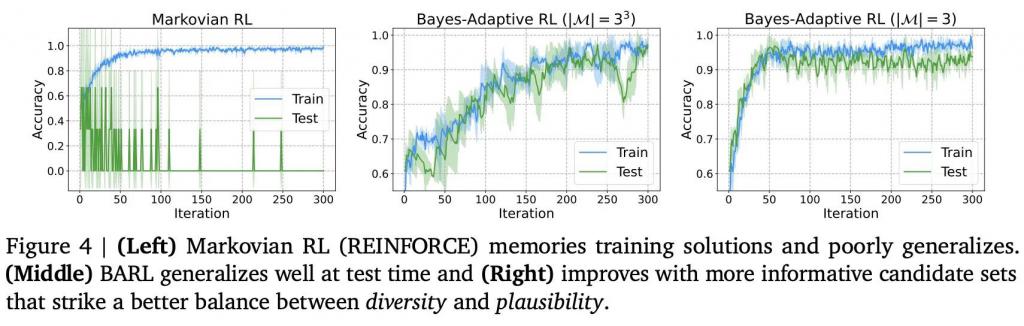
可以看到,左图中马尔可夫 RL 模型训练时成绩很快逼近 100% 但测试时几乎完全失败,中图的 BARL 模型则不仅训练表现提升,在测试时也取得了显著的高准确率。
值得注意的是,右图显示如果事先给予 BARL 一些关于任务结构的先验知识(例如 " 奖励模式就是某个字符重复三次 "),它的收敛速度和最终成绩还会更好。
这说明了候选策略既要有多样性以覆盖未知情况,又要有合理的可信度以不至于无谓浪费精力。
数学推理任务:性能全面提升,显著节省 Token
研究人员还将 BARL 应用于 LLM 的数学推理领域,并比对了 GRPO 和 "Progress" 奖励基线(给予正确答案概率的分步奖励)。
BARL 在大部分基准和模型上都取得了更高的准确率。
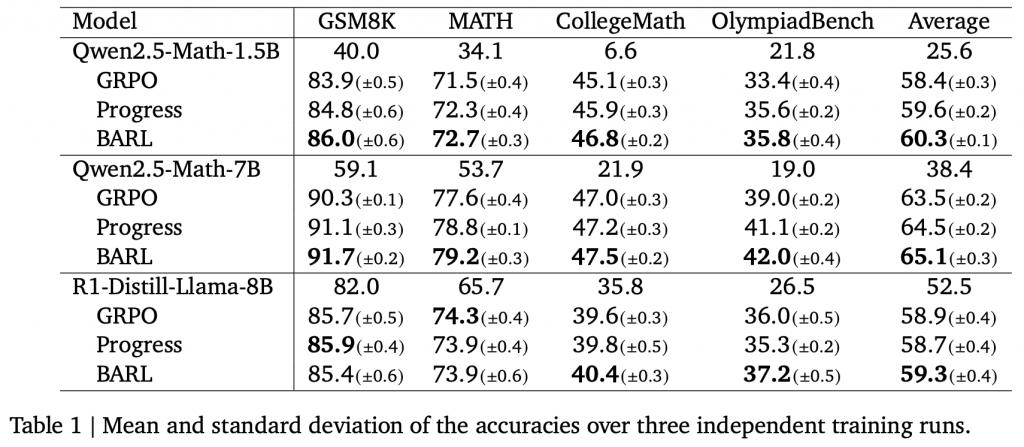
不仅如此,BARL 还展现出更高的的效率优势。
作者特别度量了每种方法为解出题目所耗费的 token 数量,结果发现在达到同等甚至更高准确率的情况下,BARL 生成的内容要短得多。

这意味着,BARL 模型并不会为了 " 多反思几次 " 而付出冗长啰嗦的代价,反而因为每次反思都更有针对性、更有效。
作者还观察到另一个有趣的现象:反思次数本身并非决定性能的唯一因素。
基础模型往往出现很多徒劳的反思,并没有带来实质的信息增益。相比之下,BARL 的反思行为更加 " 有目的性 "。
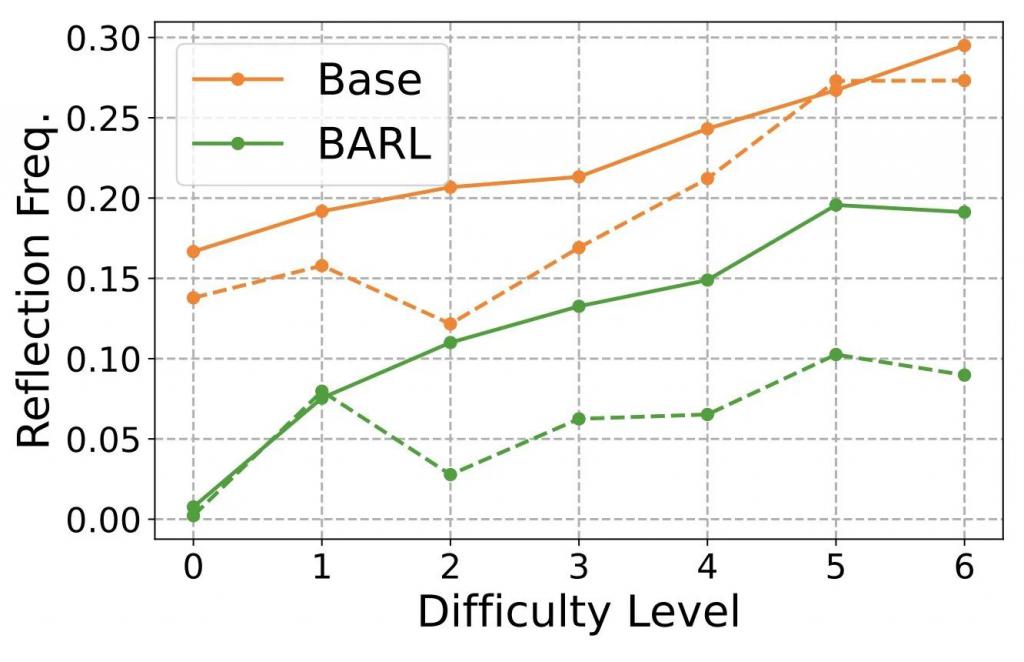
研究者计算了模型在每一步产生的思维链的贝叶斯价值,简单理解就是综合考虑了 " 这一步对最终求解有多大贡献 " 和 " 这一步带来了多少信息增益 " 的一个评分。
结果发现,BARL 模型每一步动作的贝叶斯价值始终显著高于传统 RL 模型,说明它选的步骤要么就是对解题有帮助的(高回报),要么就是探查了新的可能路径(高信息增益),从不盲目浪费步骤。
而反观基础模型,尽管某些时候看似也输出了很多自我检查的内容,但由于没有有效利用信息更新,它这些 " 反思 " 步骤的价值评估很低,往往流于表面形式。
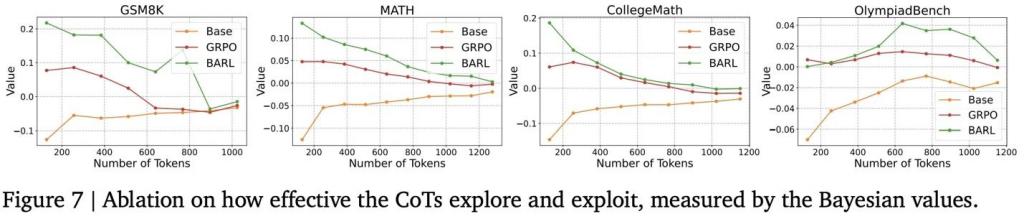
最后,作者专门训练了一个长度受限的 GRPO,人为限制它最多只能输出 32 个 token 的解题过程,强制模型倾向于不展开推理,直接给出最终答案。
可以发现模型的训练准确率最终能收敛到跟正常 GRPO 相似,而生成的过程长度却越来越短,几乎退化为直接背答案。
换言之,马尔可夫型 RL 在训练时确实可能通过牺牲思考过程而达到最优,但这样的策略一旦在测试遇到新题就会碰壁。这更加验证了传统 RL 并不能解释反思探索的好处,也不能包装自我反思的涌现。
最后,研究人员已经放出了训练代码和论文。
本文一作张申傲是美国西北大学二年级博士生,研究方向涵盖大语言模型与强化学习,尤其关注 LLM 的对齐,推理,以及智能体。其研究旨在构建能够主动获取信息并自我提升以实现超越人类水平的智能系统。

训练代码:
https://github.com/shenao-zhang/BARL
论文:
https://arxiv.org/abs/2505.20561
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见