{kind=link}
搜索Agent最新高效推理框架:吞吐量翻3倍、延迟降至1/5,还不牺牲答案质量
AI 越来越聪明,但如果它们反应慢,效率低,也难以满足我们的需求。
大语言模型(LLM)驱动的搜索智能体,通过动态拆解问题、交错执行 " 思考 "(推理)和 " 查找 "(检索)来解决复杂任务,展现了惊人能力。
然而,这种深度交互的背后,也隐藏着显著的效率痛点。
处理复杂任务时,查得慢、查得不准,都会拖慢整个流程。
来自南开大学和伊利诺伊大学厄巴纳 - 香槟分校的研究人员深入剖析了这些效率瓶颈,并提出了一套名为SearchAgent-X的高效推理框架。
实践表明,SearchAgent-X 实现了1.3 至 3.4 倍的吞吐量提升,延迟降至原来的 1/1.7 至 1/5,同时不牺牲最终的答案质量。

解析搜索智能体中的两大效率瓶颈因素
研究者发现,看似简单的检索环节,隐藏着两大关键的效率制约因素:
检索精度:并非 " 越高越好 " 的微妙平衡
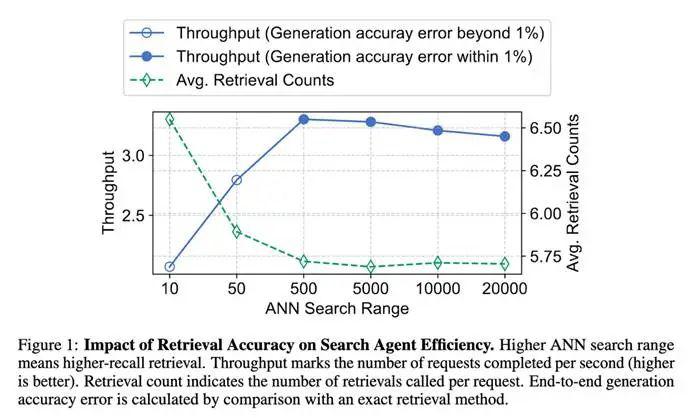
直觉上,检索越准,LLM 获取信息质量越高,效率也应该越高。但实际情况是非单调关系:
过低精度
LLM 需更多轮检索和推理弥补,总时间增加。
过高精度
检索本身计算资源消耗巨大,拖慢整体速度。
研究表明,系统吞吐量随近似检索精度先升后降。当搜索范围超过最佳点,检索成本反噬整体效率。
核心洞察:搜索智能体更青睐高召回率的近似搜索,有效支撑推理,避免不必要开销。
检索延迟:" 差之毫厘 " 引发的 " 千里之堤 " 效应
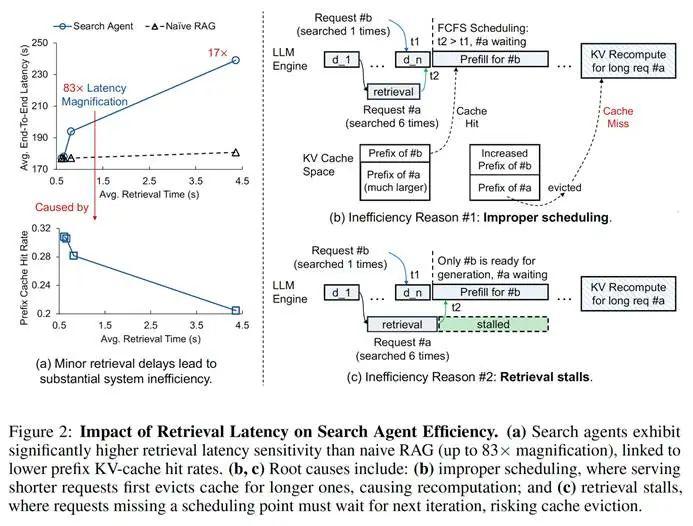
与传统 RAG 不同,搜索智能体对检索延迟极为敏感。即使微小增加,也可能导致端到端延迟急剧放大(高达 83 倍)。这与KV-cache 命中率骤降密切相关,迫使系统频繁重计算。主要原因:
不当调度(Improper Scheduling):
现象:标准 " 先来先服务 " 可能让短任务抢占长任务计算资源。
恶果:长任务宝贵 KV-cache 被 " 挤掉 ",恢复执行时不得不重算。数据显示,高达55.9%的 token 被不必要重计算。
检索停滞(Retrieval Stalls):
现象:异步检索和生成可能时间错位。长任务检索结果在下一轮生成 " 窗口期 " 之后返回。
恶果:任务错过当前调度批次被迫等待,KV-cache 可能被挤占。平均而言,超过25%的序列在完成检索后会经历此类停滞。
SearchAgent-X 的两大 " 加速引擎 "
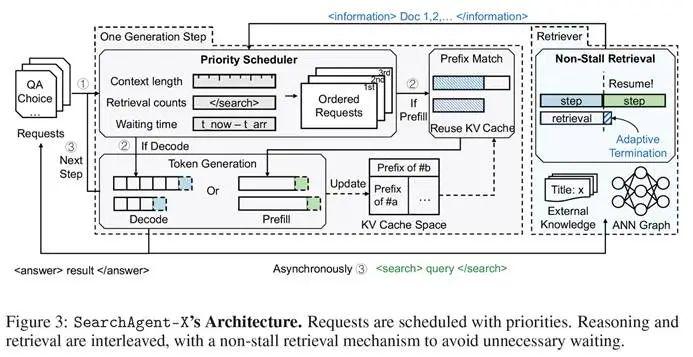
基于上述洞察,SearchAgent-X 通过智能调度与自适应检索,最大限度减少延迟,最大化 GPU 资源利用率,尤其提升 KV-cache 的有效利用。
利器一:优先级感知调度 ( Priority-Aware Scheduling )
解决不当调度问题,SearchAgent-X 引入优先级调度,动态排序并发请求。
调度依据:综合考虑:
已完成的检索次数:检索越多,计算成果越多,缓存复用价值越大。
当前序列的上下文长度:指向更长、可复用的缓存。
请求的等待时间:确保公平。
核心理念:" 让最有价值的计算优先 ",减少无谓等待与重复劳动。
利器二:无停顿检索 ( Non-Stall Retrieval )
缓解检索停滞,SearchAgent-X 实现灵活、非阻塞式检索提前终止策略。
执行逻辑:自适应判断是否 " 见好就收 ",依据:
检索结果的成熟度:新信息带来的质量提升甚微时,认为结果已足够好。
LLM 引擎的就绪状态:判断 LLM 是否准备好下一轮计算。
核心理念:当检索结果足够成熟且 LLM 引擎就绪时,SearchAgent-X 停止检索。这种机制是恰到好处的 " 放手 ",保证信息质量同时,让生成过程无需不必要的等待。
实战检验:效率与质量双丰收
研究者在 Qwen-7B/14B 等模型上,对 SearchAgent-X 与多种基线系统进行了全面对比。
端到端性能:吞吐与延迟的显著优化
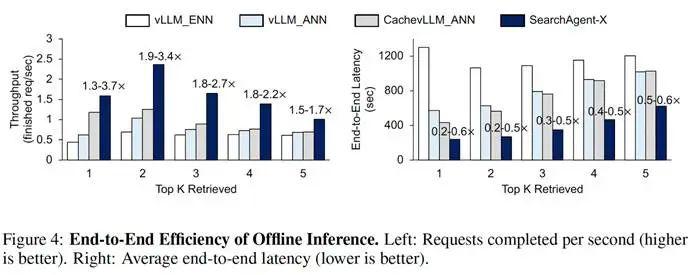
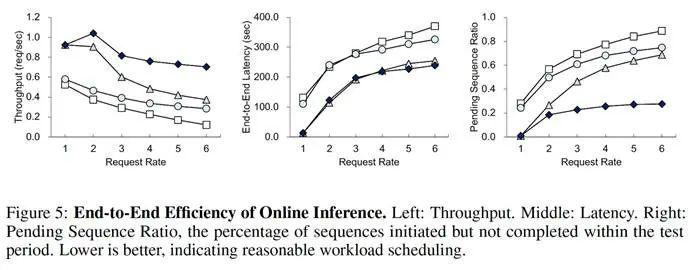
离线推理 ( 所有请求一次性到达 ) :在 Musique 数据集上,SearchAgent-X 的吞吐量比基线系统高出1.3 至 3.4 倍,平均延迟降低至基线系统的20% 至 60%。
在线推理 ( 请求持续到达 ) :SearchAgent-X 完成的请求数量比基线系统多 **1.5 至 3.5 倍。请求速率越高,其优势越明显,最多时是某些基线的 5.8 倍。
生成质量:效率提升,效果不打折
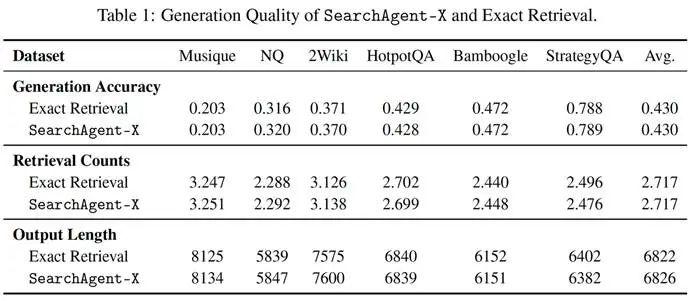
在 Musique, NQ, HotpotQA 等六个代表性数据集上的评估表明,SearchAgent-X 在生成准确率上,与采用精确检索的基线系统表现相当。
有趣的是,在某些数据集上,由于近似检索带来的轻微扰动促使模型进行额外推理,其准确率甚至略有提升。
技术拆解:每一项优化都 " 功不可没 "
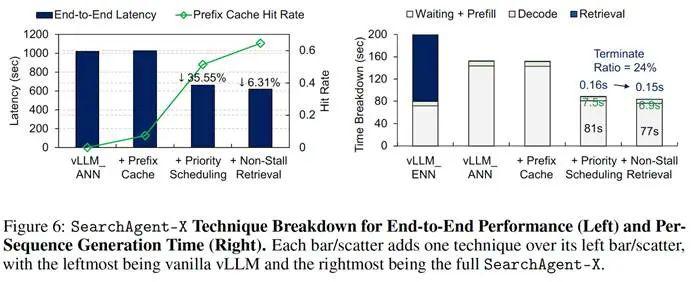
消融实验揭示各组件贡献:
优先级调度
在引入缓存基础上,将端到端延迟降低 35.55%,KV-cache 命中率从0.07 提升至 0.51。
无停顿检索
在前两者基础上,进一步将 KV-cache 命中率提升至 0.65。它平均仅使检索时间减少 0.01 秒,却显著降低端到端延迟,印证了 " 差之毫厘的等待,影响深远 "。
总结与展望
未来的 AI 要解决更宏大、更开放的问题,必然需要更频繁地与外部工具和知识库交互,而这恰恰是效率瓶颈所在。
SearchAgent-X 揭示了:
平衡之殇
在 AI 智能体中,任何单一工具(如检索)的性能并非越高越好,需要与智能体的整体工作流相匹配。
等待之痛
在由多个异步组件构成的复杂 AI 系统中,微小的延迟和不当的资源调度会被急剧放大,造成雪崩效应。
该研究通过引入优先级感知调度和无停滞检索两项机制,显著提升了搜索型 AI 智能体的推理效率和响应速度。
实验表明,这些优化在不牺牲答案质量的前提下,有效缓解了深度交互中的延迟与资源浪费问题。相关方法可为包括搜索引擎、企业问答系统在内的多类复杂 AI Agent 提供实践参考。
论文地址 : https://arxiv.org/abs/2505.12065
Github 地址 : https://github.com/tiannuo-yang/SearchAgent-X
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见