{kind=link}
推理大模型1年内就会撞墙,性能无法再扩展几个数量级
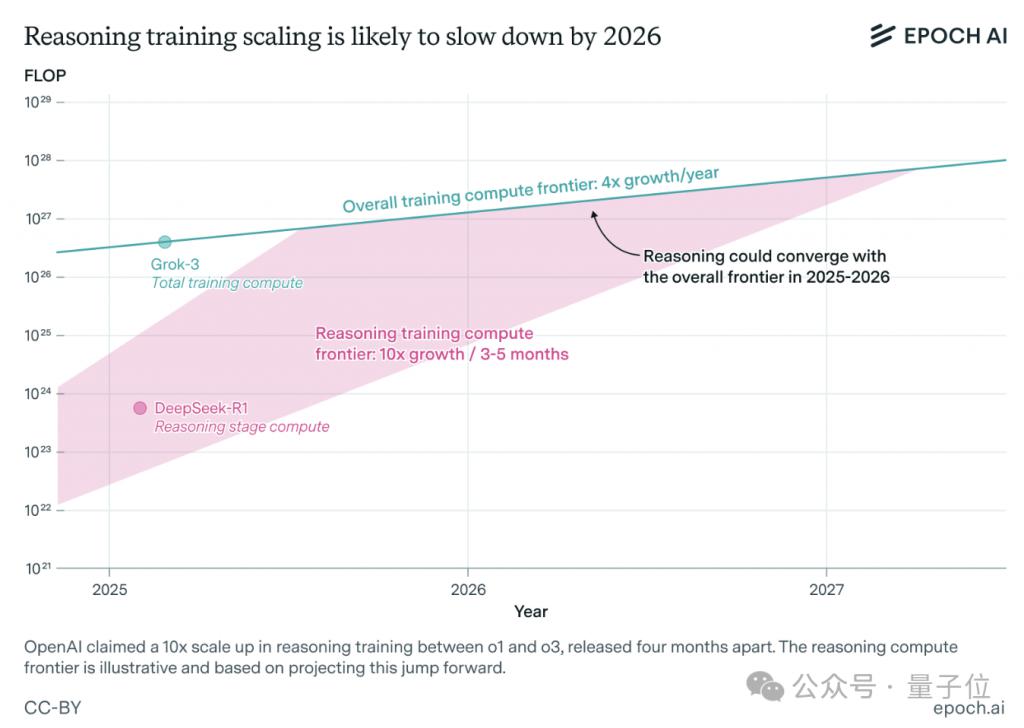
一年之内,大模型推理训练可能就会撞墙。
以上结论来自 Epoch AI。
这是一个专注于人工智能研究和基准测试的非营利组织,之前名动一时的 FrontierMath 基准测试(评估 AI 模型数学推理能力)就出自它家。
与之伴随而来的还有另一个消息:
如果推理模型保持「每 3-5 个月都以 10 倍速度增长」,那么推理训练所需的算力可能会大幅收敛。
就像 DeepSeek-R1 之于 OpenAI o1-preview 那样。
看了这个结果,有围观网友都着急了:
既然在 o3 基础上再 scaling 非常困难,那为啥咱不探索模块化架构或针对特定任务的专用模型呢?
" 效率 " 比 " 研究过剩 " 更重要!

推理训练还有 scalable 的空间
OpenAI 的 o1 是推理模型的开山之作。
和 o3、DeepSeek-R1 等一样,它们从传统的大语言模型发展而来,在预训练阶段使用了大量人类数据进行训练,然后在强化学习阶段(也就是所谓的第二阶段),根据解题的反馈来改进自己的推理能力。
虽然推理模型已经成为了很多 AI 使用者的实用帮手,但关于推理训练所需算力的公开信息非常少,大概只有以下这些:
OpenAI 表示,与 o1 相比,训练 o3 所需的算力提升了 10 倍——提升部分几乎都花在了训练阶段。
OpenAI 没有公开 o1、o3 的具体细节,但可以从 DeepSeek-R1、微软 Phi-4-reasoning、英伟达 Llama-Nemotron 等其它推理模型。它们所需的推理训练阶段算力耕地,但可以根据它们进行推演。
Anthropic 的创始人兼 CEO Dario Amodei 曾针对推理模型有过一篇公开文章。
然后就没有然后了……
根据现有的信息和资料,Epoch AI 进行了总结和分析。
首先,OpenAI 公开过这样一张图表,上面展示了 o3 和 o1 在 AIME 基准测试中的表现,以及两者在推理训练阶段可能所需的算力的对比——
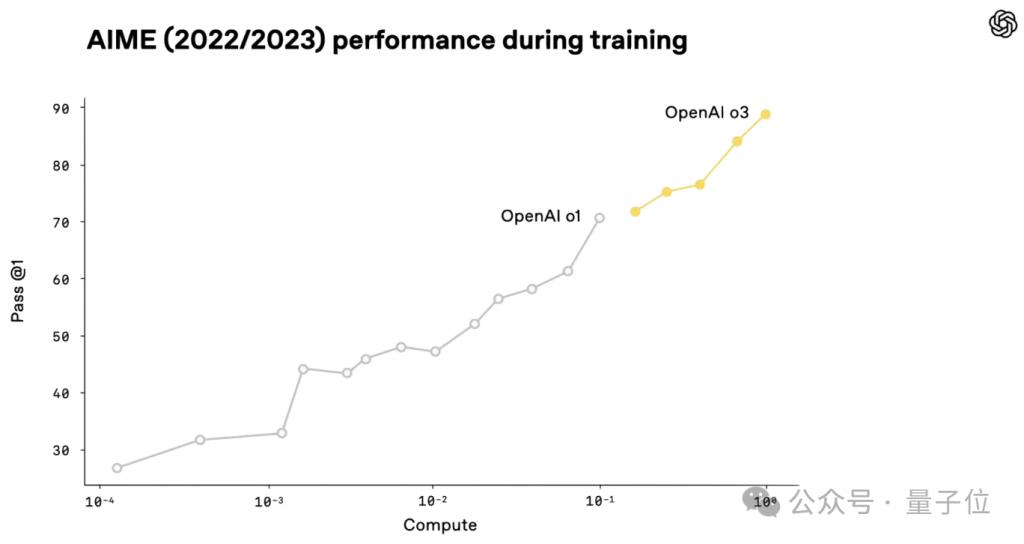
可以看到,终版 o3 花费的算力是 o1 的 10 倍。
Epoch AI 分析道:"x 轴很可能显示的是推理训练所需算力而不是总算力。"
Epoch AI 罗列了这一猜测的证据。
第一,初代 o1 耗费的算力比 o3 低四个数量级,其在 AIME 上的得分约为 25%。
如果 x 轴表示总计算量," 不太可能呈现这种情况 "。
第二,如果 x 轴表示的是所需总算力,这张图意义就不大了。
因为这就意味着 OpenAI 训练了 N 个版本的 o1,且预训练阶段非常不完整。

依照 Epoch AI 的猜测,如果 o3 在推理结算花费的算力是 o1 的 10 倍,这意味着什么?
由于很多推理模型背后团队都学精了,并不公开训练方法和过程,所以只能从现有公开资料里去寻找答案。
比如 DeepSeek-R1。
Epoch AI 此前估算,DeepSeek-R1 推理训练中使用的算力约为 6e23 FLOP(成本约 100 万美元),需要生成大约 20 万亿个 tokens ——这只有 DeepSeek-V3 预训练成本的 20%。
虽然只是一种估算,但 R1 在各个榜单上的得分和 o1 非常接近," 因此可以用它来为 o1 所需算力设定一个 baseline"。
比如英伟达的 Llama-Nemotron Ultra,它在各个基准上的分数与 DeepSeek-R1 和 o1 相当。
它是在 DeepSeek-R1 生成的数据上训练的。
公开信息显示,Llama-Nemotron Ultra 的推理阶段耗时 140000 H100 小时,约等于 1e23 FLOP。这甚至低于它的原始基础模型预训练成本的 1%。
再比如微软的 Phi-4-reasoning。
它是在 o3-mini 生成的数据上训练的。
Phi-4-reasoning 在推理阶段规模更小,成本低于 1e20 FLOP,可能是预训练所需算力成本的 <0.01%。
值得注意的是,Llama-Nemotron 和 Phi-4-reasoning 都在 RL 阶段之前进行了有监督微调。
咱们再来看看今年 1 月 DeepSeek-R1 发布后,Anthropic 的 CEODario Amodei写的一篇文章,这被视为关于现有推理模型所需算力规模的最后一点线索:
由于这是新范式,我们目前仍处于规模拓展的初期阶段:所有参与者在第二阶段投入的资金量都很少,花费从 10 万美元提高到 100 万美元就能带来巨大收益。
如今,各公司正迅速加快步伐,将第二阶段的规模扩大到数亿乃至数十亿美元。
有一点必须重视,那就是我们正处于一个独特的转折点上。
当然了,Amodei 对非 Anthropic 模型所需算力的看法可能只基于自家公司内部数据。
但可以清晰了解,截至今年 1 月,他认为推理模型的训练成本远低于 " 数千万美元 ",大于 1e26 FLOP。
Epoch AI 总结道——
上述的预估和线索指向一个事实,那就是目前最前沿的推理模型,比如 o1,甚至 o3,它们的推理训练规模都还没见顶,还能继续 scalable。
但 1 年内可能就撞墙了
换句话说,如果推理训练还没见顶,那么推理模型还是有潜力在短期内快速实现能力拓展的。
这就意味着,推理模型还很能打,潜力巨大。
就像 OpenAI 展示出的下图,以及 DeepSeek-R1 论文中的图 2 一样——模型答题准确率随着推理训练步骤的增加而大致呈对数线性增长。
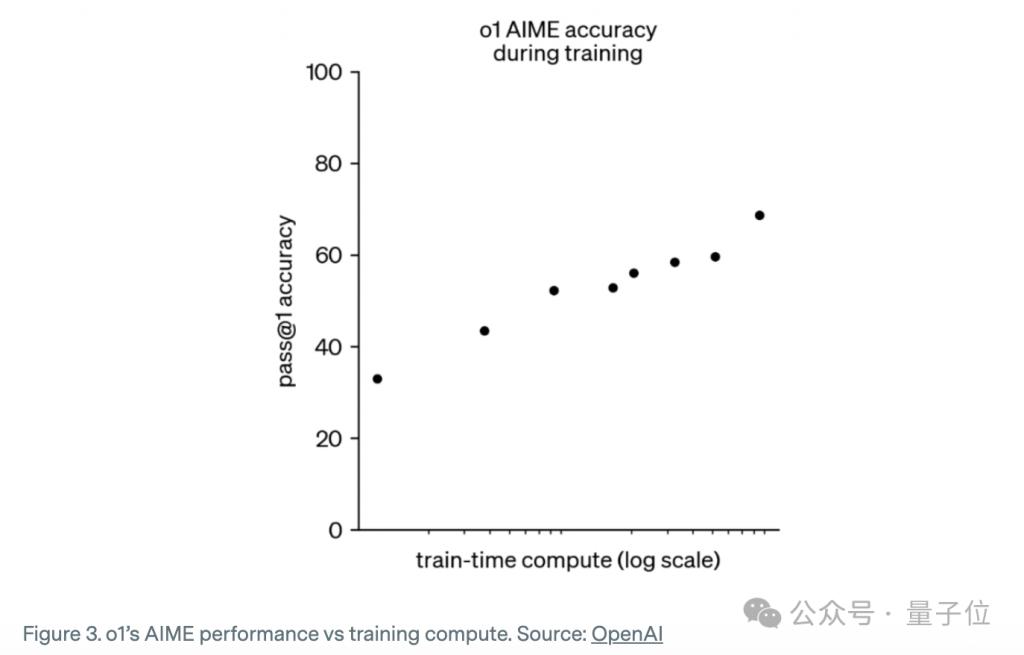
这表明,至少在数学和编程任务上,推理模型的性能随着推理训练的扩展而增强,就像预训练的 scaling law 一样。
行文至此处,Epoch AI 写下这样一段话:
如果推理阶段的算力需求见顶,那么其带来的增长率将收敛,大概是每年增长 4 倍。
绝不会像 o1 推出后 4 个月就有了 o3 那样,保持几个月增长 10 倍的态势。
因此,他得出这样一个结论——
如果一个推理模型的训练阶段仅比前沿推理模型低几个(比如说少于三个)数量级,这种增长率可能在一、两年内减缓,甚至撞墙。

然鹅,想要扩展推理模型并不是那么简单的。
单单是数据不够这一项,就可能导致其停滞不前。
大家也都还不清楚,除了数学、编程领域,推理训练是否能泛化到其它规律性没那么强的领域。
但可以肯定的是,随着推理模型的训练越来越成熟,所有推理模型所需的成本可能都趋同。
虽然研究成本的高低并不影响算力和性能之间的关系,但如果相关研究保持 " 花钱如流水 " 的状态,那么推理模型可能无法达到人们心中预期的最佳水平。
另一方面,即使所需算力的增长速度放缓,推理模型也可能持续进化,就像 R1 那样。
换句话说,不只有数据或算法创新能推动推理模型的进步,算力大增也是推动推理模型进步的关键因素。
参考链接:
https://epoch.ai/gradient-updates/how-far-can-reasoning-models-scale
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!